


AI Security: Current Solutions and Open Challenges
The state of AI security solutions, and what's next

You can find the first part of the AI security series here, which provides an overview of why AI security challenges are different, and the main types of vulnerabilities.
This article dives into current approaches for mitigating such risks, including best practices, the current landscape of tools, and experimental methods. Main takeaway – while there are ways to prevent certain risks, no one method is foolproof, and many are still works in progress.
The figure below, published in Stanford’s inaugural AI index, demonstrates how leading models are susceptible to exploitation by bad actors, as they still provide harmful responses with different levels of severity. However, these models were evaluated against one benchmark, also underscoring the lack of benchmarks and standards for evaluating safety across AI models.
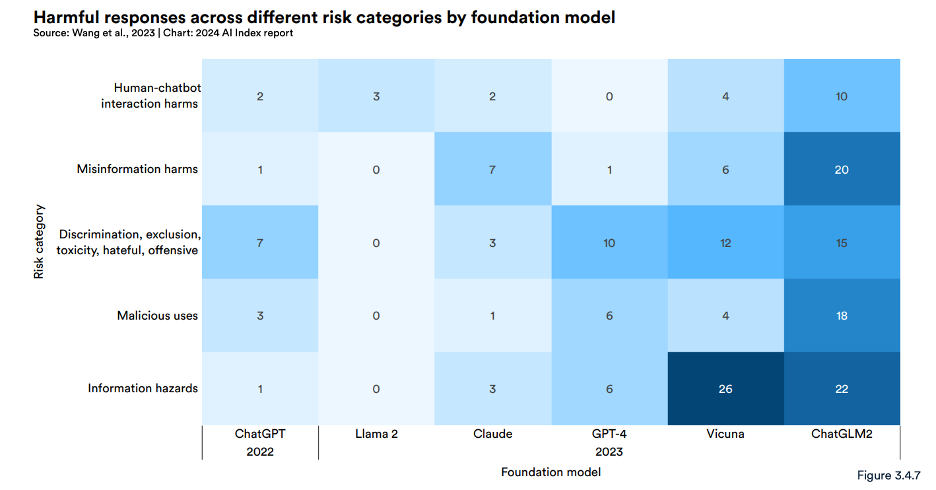
Source: Stanford AI Index 2024, Chapter 3.4 – Security and Safety
Mitigation Measures
Some vulnerabilities mentioned in the first article do not have direct solutions. Instead, they require organizations to secure their infrastructure and implement best practices to reduce any potential risks. Emerging third party solutions provide customized solutions for specific the AI use cases and organizational needs, addressing areas such as shadow AI/LLM use, incident response and detection, and verification of LLM activities.
Best practices for addressing ML security threats include:
Data sanitation: this involves reviewing and securing user inputs and model outputs. Methods include anonymization, data masking techniques, encoding outputs, or end-to-end encryption to protect data and prevent attackers from gleaning information about the model to optimize their targeting. Additionally, techniques such as encoding outputs can prevent the execution of malicious code. Data sanitation is also important because proprietary enterprise data that is uploaded to open-source models can become part of its future training data, with legal and compliance ramifications.
Data validation: users might uncritically trust model outputs, which could include malicious content or anomalies. Cross-referencing the outputs and decreasing excessive usage or dependency on such tools can potentially prevent unforeseen vulnerabilities.
Input pre-processing: reviewing model inputs in order to catch potentially malicious and unusual prompts before they pass through the rest of the machine learning process. If attackers seek to prompt the model in order to understand its ontology and decision-making framework, pre-processing inference data and model inputs can add randomness to further complicate attackers’ attempts.
AI safety evaluations: involves evaluating model outputs based on content and risk filters, but can potentially be circumvented. Additionally, this involves auditing the security of third-party tools and monitoring these tools for potential threats.
Code signing/ Identity verification: involves verifying users’ identity before accessing models in production or potentially executing harmful code.
User Interaction Limits: limiting the number of queries from a user, preventing hackers from constantly bombarding the model with inputs, and ensuring that they receive minimal information to potentially infer the model’s architecture and blueprint.
Adversarial training: this method has been one of the most effective to make models more robust, but the high computational requirements of LLMs and newer models present a need for scalable adversarial training algorithms to address attacks such as jailbreaking. Other techniques such as network distillation which decreases the size of the model and makes it more generalizable, can also prevent adversarial attacks.
Ensemble of models: some attacks are tailored towards specific models or model architectures, but relying on multiple models for inference can provide more security against malicious inputs.
These methods tend to be “works in progress” because they require constant iteration and testing:
Hallucination/ground truth detection: data flows can be monitored to detect abnormal patterns, and even model outputs that seem real but are not supported (such as nonexistent software packages), and fine-tuned claim evaluation models in order to detect potential hallucinations using source documents.
Improved meta prompts: meta prompts are messages used to improve model performance and deliver intended outputs. They can potentially guard against prompt injection attacks that seek to manipulate the model’s behavior, by acting as guardrails during the output generation process. But, they require significant testing and customization based on the specific profile and intended goals of the model, and may not cover all attacker scenarios.
Third-party tools tend to offer more flexibility and features in implementing the following approaches:
Model monitoring: evaluating the model overtime can provide signs of potential data poising due to concept or training data drift.
Prompt injection detection: new models seek to identify indirect prompt attacks and jailbreaking attempts by analyzing the content, structure, and intent of these inputs.
Deployment methods: model distribution methods can increase, or decrease the attack surface area. For example, edge devices provide a greater number of points (hardware, software, network) that attackers can access to obtain sensitive information, proprietary models, and model development methods. Apple’s partnership with Open AI to add their technology to While cloud deployment provides more security, it still has its own set of security challenges and vulnerabilities.
Artifact and product scanning: ML artifacts (any outputs such as scripts, data models, model checkpoints, etc.) or products produced by downstream applications are checked for potential modifications and exploits.
Current ML / LLM security market
Current solutions are mainly focused on the following areas:
Organizational data protection, or data security posture management, but with a specific focus on AI (Normalyze, Noname, Cyera, Sentra)
Model security, including threats such as prompt injection and direct attacks against LLMs (Lasso Security, Calypso AI, Protect AI)
Browser and application security, in order to prevent potential vulnerabilities if individuals in a company use third-party models (Island Security, LayerX, Nightfall AI, AIM Security, Cyberhaven, Oligo Security)
AI “Firewalls”, which prevent unauthorized or suspicious network traffic and threat detection (Prompt Security, Robust Intelligence, Troj.ai)
Secure development platforms, which involve red teaming, continuous monitoring, and secure ML model development (Lakera, Adversa)
What’s next for ML Security?
The amount of corporate data employees put into AI tools increased by almost 500% between March 2023 and 2024, according to Cyberhaven. Employees are relying on tools such as AI coding assistants, or administrative co-pilots to improve productivity, but they can present more opportunities for security and data breaches. In addition to secure coding practices (safeguarding proprietary codebases, mechanisms to prevent loading of untrusted code), overall AI literacy is also a key factor for successful security implementation, since non-technical and expert users are increasingly depending on these tools. Furthermore, AI Agents, or software that can autonomously perform tasks for users, make decisions, and interact with other applications, are also targets for attacks, since they can provide bad actors with a greater level of control to perform unauthorized actions. Attack automation is also a concern, as cyberattacks can also be facilitated and automated by LLMs by generative AI chatbots and conducting penetration tests. This can be especially effective for automating post-breach attacks to further obtain credentials, find vulnerabilities in an infected networks (lateral movement), etc. In any case, as these technologies improve, attackers’ tactics will likely become more advanced as well.
Further reading: