
How is AI Infrastructure Optimization Evolving?
As AI capacity needs continue to shift, what are the key drivers in the space?

In a previous piece on AI infrastructure optimization, I discussed the role of software and hardware infrastructure improvements in allowing AI development to scale and meet growing computational demands. The primer mainly focused on different layers in the AI infrastructure stack where optimizations are possible and most effective– at the data-level, model-level (such as orchestration and deployment) hardware level, and the software-hardware boundary.
Since then, many new startups have emerged, tackling existing optimization problems (Pruna.ai, focused on model compression, ZML for inference), and presenting new approaches to make the most of AI hardware (mkinf, Fal, and Flex.ai, focused on compute efficiency from different perspectives).
This article explores some of these new ideas and open challenges in optimizing AI infrastructure that will continue to shape the evolution of this space.
To recap, the main drivers of AI infrastructure optimization include:
GPU scarcity and mismatch between supply and demand, which also varies based on the application-specific requirements and phase of development,
Long-term sustainability of cloud-centric approaches and increasing “lock-in” from vendors for both training and inference
Power consumption and costs - making the most of idle GPUs, and managing spikes and decline in demand is still an issue along with significant costs
Latency and performance
Security and privacy of processed data
Different infrastructure demands throughout the AI development lifecycle (such demands tend to be consistent during the training phase, but highly variable during the inference phase due to real-time usage)
Data center demands and hardware availability, which are also affected by geographical considerations
Fragmentation of infrastructure - namely the number of vendors, platforms, and options that have different advantages and disadvantages
Given the number of variables involved, one single optimization method might not become dominant. Instead, based on unique workload and use case requirements, infrastructure optimization will likely include a combination of optimizations at multiple levels of the development stack.
However, a few open questions remain, and some trends are becoming more salient as this space continues to grow.
Data center needs and capacity
Some infrastructure providers, such as “serverless” GPU services, are building their own data centers. However, there are significant capital expenditure costs and challenges in maintaining these centers. Downtime, for one, is expensive, and can come from various sources. About 40% of cases are due to battery failure or accidental or human error, while the remaining 60% are caused by generator failure, IT equipment failure, water, heat or CRAC (computer room air conditioning) failure, or weather-related issues. These issues, mainly due to design, maintenance, or operational processes, means lost sales, damage to the center’s brand and reputation, lost data, payouts, and lost productivity. Addressing this requires integration between different processes, and procedures for preventing human error. In addition, operational challenges that data centers are dealing with include implementing proper control mechanisms, levels of automation, capacity planning, and minimizing risk sources that could lead to breaches, as well as increasing interoperability between facilities, IT, and business management.
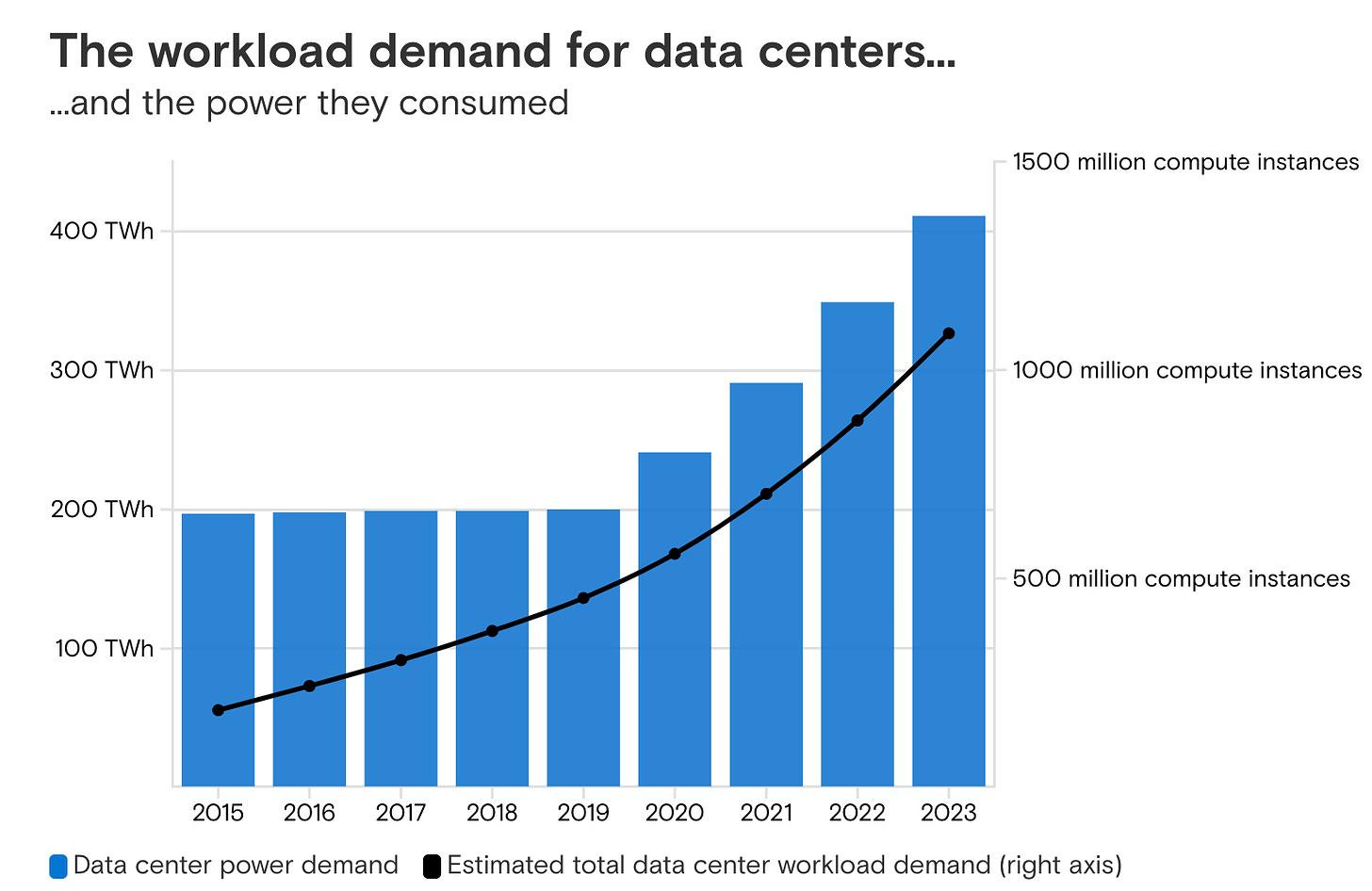
Source: AI poised to drive a 160% increase in data center power demand
AI infrastructure demands have put additional requirements on data centers, due to the sheer volume of data being processed and computational demands for AI model training and inference. As a consequence, energy and latency requirements must also be optimized, in order to ensure effective usage of data center resources. mkinf, for example, mainly focuses on distributed inference, and sits in between data centers and generative AI companies. On the one hand, their platform addresses inefficiencies from idle GPUs, and helps data centers make the most of their AI hardware by making it available to developers through their platform. At the same time, they also match AI application developers and companies with optimal infrastructure configurations, giving them flexibility with compute options while ensuring high performance.
They also offer a new perspective on edge computing: considering data center constraints and disproportionate demand, edge computing could also mean running AI models on the data center hardware that is closest to the users, which are underutilized compared to data centers in in-demand locations.
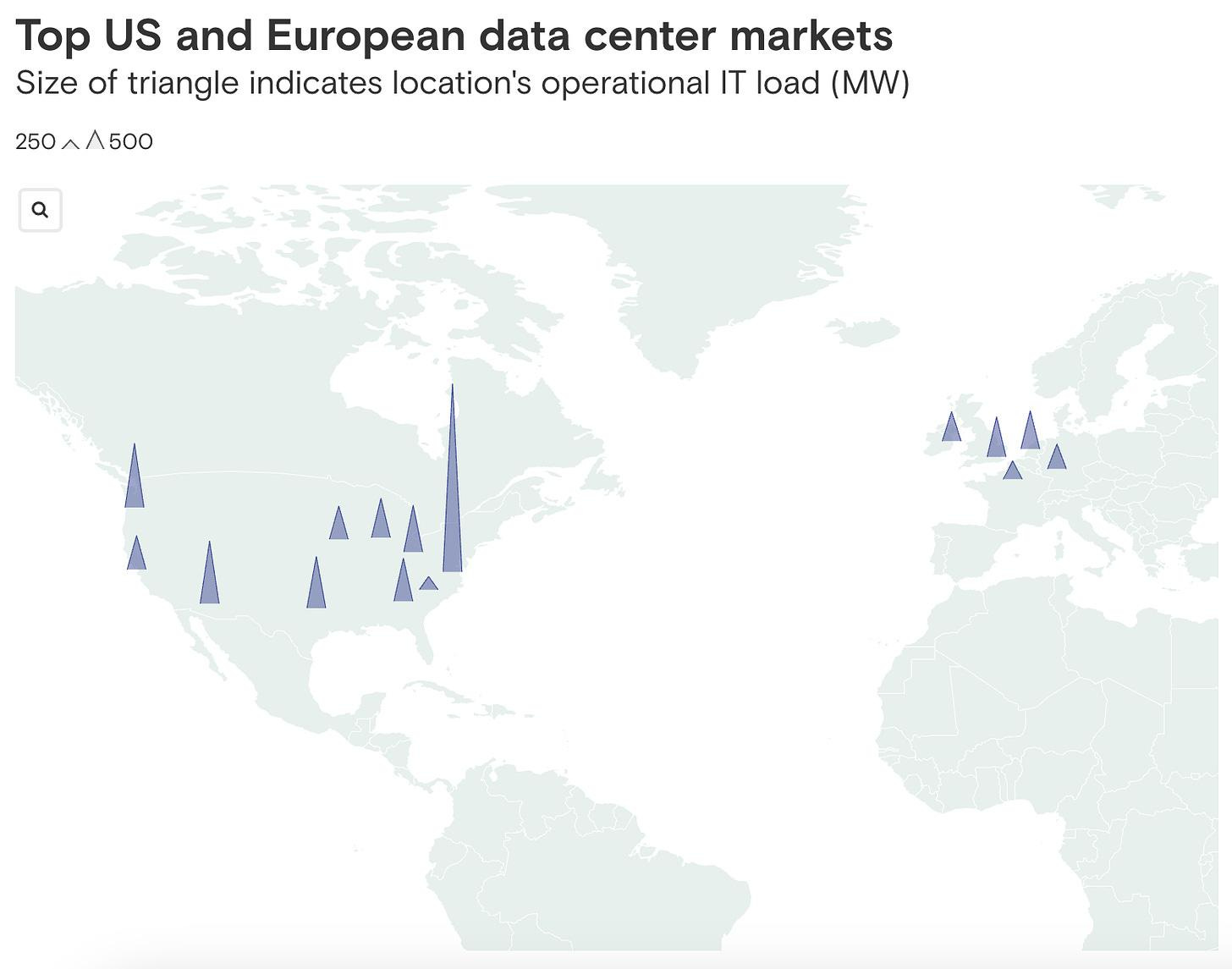
Source: AI poised to drive a 160% increase in data center power demand
Environmental and efficiency considerations
The main sustainability metrics and considerations for data centers include basic power consumption, and power usage effectiveness (PUE) which not only have environmental impacts but also directly affect efficiency and performance. However, regulators are also seeking more granular data for factors such as water consumption, cooling and heating, renewable energy usage, equipment waste and lifecycle data, and overall energy costs. However, some of these metrics are difficult to measure, and the quality and nature of data collection may vary due to lack of standardization for these metrics across data centers.
Sustainability progress, however, is more promising. According to a survey of data center executives in 2024, 80% of executives mentioned that costs, improving energy performance and forecasting future data center capacity requirements were among their top priorities.Cooling and heating requirements for AI hardware are being addressed through air cooling, air-assisted liquid cooling, digital boiler technology, and liquid to chip cooling deployment. However, there is a shortage of critical components in the liquid cooling supply chain, which is concerning as SOTA chips such as next-gen NVIDIA chips depend on liquid cooling. Meanwhile, other areas are being explored, such as immersion cooling and heat reuse, or recapturing waste heat from services and redirecting it to other areas, as excess heat can also negatively impact cooling systems.
Semiconductor companies such as Infineon and Texas Instruments are investing more in GaN power devices, which provide more advantages such as increased power density and reduced cooling requirements. These advancements are promising for data centers as they can help meet the infrastructure demands for AI development. Other areas that are being explored to improve data center AI infrastructure include: machine-learning software to monitor and optimize chilled water plants, increasing power draw per rack, net-zero data center initiatives, incorporating renewable energy sources, and optimized control strategies for energy savings. This is especially crucial as older data center facilities and new facilities compete to secure high-powered computing, and need to improve their own infrastructure to meet current demands from AI companies and developers.
Other drivers of efficiency for AI-focused data centers include:
Power distribution and flexibility
Server placement and flexibility
Shared physical infrastructure for different types of hardware
Enabling efficiency of fiber to interconnect servers
Colocation of server and network hardware
Disproportionate demand based on type of developer/enterprise size and needs, number of users
Pivots in response to changes in the AI space
Needs depending on type of application
Multimodal workloads
Currently, many use cases are focused on language models and chatbots, but there has been a proliferation of companies developing solutions for video, images, and multimedia AI. However, given the unique compute requirements for multimodal AI use cases and data types besides text, new solutions have also emerged. For example, there are some platforms that allow developers to run specific models, such as ThinkDiffusion, or RunDiffusion that are meant for Stable Diffusion Models. Other companies such as Fal have developed their own platform for changing workload needs for multimedia generative AI, and are providing compute for visual AI inference, such as text-to-image, image-to video models and more. Runware is also building their own servers in order to supercharge inference for image generation models, seeking to abstract developers’ AI hardware infrastructure needs. Additionally, they consider other drivers of optimization mentioned above – namely pricing and energy costs in a way that is specific to AI workload needs. While meeting demands for higher-density workloads is not an immediate issue, compared to improving energy efficiency, it is still an emerging topic on the horizon for data centers.

Source: Global Survey of Data Center and IT Managers, 2024
Universal AI compute
There is also an emerging notion of “universal AI compute”, or AI infrastructure offerings that are vendor-agnostic. In this case, the matching process involves assessing the developer’s use case, and allocating available compute based on user requirements and the relevant architecture for those needs. Along with mkinf, Flex AI is another example – their platform considers the particular use case and provides compute accordingly, taking care of differences and conversions among different software-hardware ecosystems for hardware vendors. While the majority of AI workloads still depend on NVIDIA chips, there are still benefits and trade-offs associated with different chips, whether it is NVIDIA, Intel, AMD, or other providers, based on the given workload, AI development lifecycle stage, scale of usage, and essential parameters for optimization. As developers often focus more on the application side and less on infrastructure, determining the right infrastructure needs can be complex and overwhelming, and lead to suboptimal choices. Even AMD has recently acquired ZT Systems in order to build out their software ecosystem to reach more developers, and leverage the startup’s data center infrastructure business to enhance their systems for AI inference and training. Data centers also need to integrate chips that don’t run on NVIDIA’s CUDA ecosystem, and new solutions are providing that interoperability and access to other ecosystems.
What will next-gen AI infra look like?
Building sustainable data centers for AI needs and harmonizing different layers of the infrastructure stack for both providers and developers are two themes that are becoming more and more salient. According to a recent report, data center supply under construction in North America has increased 70% from last year, to 3.9 gigawatts. At the same time, AI hardware needs might surpass existing supply - leading to the emergence of infrastructure orchestrators that align continuous data center and developer needs.
If you’re building in this space or if you have any thoughts on the article, feel free to reach out here.
Thanks to Veronica Nigro for her insights and feedback.