


Is it possible for AI to be neutral?
Demystifying AI ethics, safety, and alignment

Recently, many companies, individuals, and even governments have raised alarms about the need for AI safety, and “alignment”. But what exactly does this mean? And, is it possible to achieve?
First, it is important to survey the AI ethics landscape:
AI ethics means designing, developing, and implementing AI systems in a way that prevents biases and harms for individuals, groups, and society. This includes:
Fairness: how can we make sure that AI models do not discriminate against anyone? Sometimes referred to as algorithmic fairness, this ensures that AI-driven decisions and responses treat users equally, without maligning certain groups.
Responsibility: are there safeguards and accountability measures to ensure ethical and legal compliance? This includes guardrails, or mitigation measures to hold individuals or organizations accountable, and address unintended consequences.
Privacy: is the user data managed in an appropriate way? This also involves protecting sensitive and personal user and company information.
Transparency: does the system provide information about its decision making process? Such information allows independent and third-party auditors to evaluate the system for potential problems.
Explainability: based on given information, can we understand how the AI system works? In contrast to transparency, explainability means that the “blueprint” and logic behind the algorithmic decision-making processes are clear, (though it is more difficult in practice).
Responsible AI mainly refers how ethics is implemented in organizations:
Define: what does ethics mean for the specific company, and how it uses AI?
Identify: what are the business objectives and company goals?
Match: does the behavior of the system match the company’s goals, business objectives, as well as organizational and legal policies, regulations, and general ethical principles?
Human-centered AI falls under the broader human-centered or value-centered design movement, which emphasize UX and user values and needs. (Also see the previous article on responsible product design).
AI ethics continues to be a problem, as evidenced by recent cases:
Algorithms discriminating against women
Racial bias in health diagnostic software
Using drivers’ data without consent to score them and determine insurance policies
AI mistranslating words in legal cases, with significant consequences
Facial recognition systems wrongly classifying individuals for serious offenses
Synthetic media companies using individuals’ voices without their permission
Generative AI also has a values and bias problem.
Why is this a big deal? Unlike other classification and rule-based AI systems, generative AI has greater potential for applications across industries and critical use cases, as it can provide dynamic answers in real-time. However, these answers can also violate AI ethics principles, producing inconsistent, inaccurate, and biased outputs, going against the model’s original “code of conduct”.
Part of this is not only due to training data, which reflects stereotypes and biases its original context, but also due to broader approaches and values towards designing these AI systems.
A big component of AI ethics is also influenced by individuals’ perceptions and ideas about the future of AI.
Some of these scenarios range from neutral and optimistic to uncertain and apocalyptic, and influence how AI ethics are operationalized. Of course, the following areas are not mutually exclusive, but describe dominant perspectives in broad strokes.

It is disputed whether models will eventually develop human-level capabilities. The figure below shows the performance of AI models on benchmarks for reasoning tasks related to computer vision, speech recognition, language understanding, and mathematics, but these benchmarks continue to change. Once bottlenecks in compute and infrastructure are resolved, the pace of AI advancements in these abilities could be significant, due to rate of computations that can be performed.
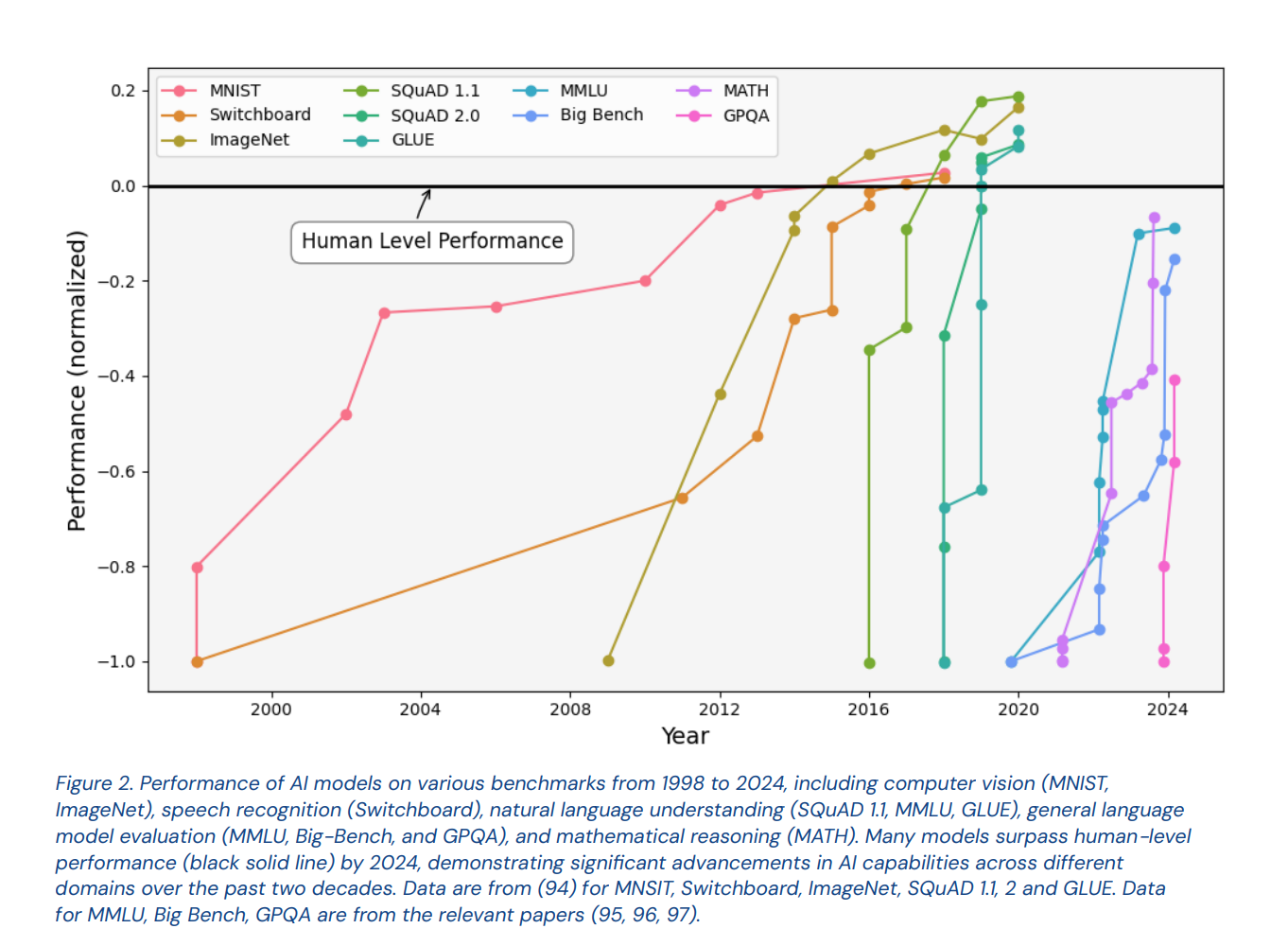
Source: International Scientific Report on the Safety of Advanced AI (p.26)
Where do “AI safety” and “alignment” come in?
The AI safety movement, in contrast to AI ethics, is motivated by the notion that AI will eventually develop human-like or “super-cognitive” abilities, also known as artificial general intelligence (AGI).
Model oversight: how can we scale approaches towards monitoring and mitigating potential harms?
Emerging behaviors: what if AI systems develop new behaviors, such as power-seeking, and how can these be prevented?
Honesty: will it be possible for AI systems to always tell the truth?
Learning values: will it be possible for AI systems to “learn” complex values?
Capability control: can we control the future tasks that AI systems self-learn?
What is the “alignment” problem?
AI alignment is a sub-category of AI safety, focused on building AI systems that are do not put people in danger – which is interpreted in a variety of ways.
According to Jan Leike at Anthropic (until recently Head of the Superalignment Team at Open AI), the main question is:
“How do we align systems on tasks that are difficult for humans to evaluate?”
For example, AI systems could potentially:
Act deceptively and manipulate users, such as to obtain a reward
Learn conflicting rules or “internalize” conflicting goals
Generalize beyond the data distributions they were fine-tuned on
Appear to be in accordance with user interests, even if they are not
Become more autonomous and evade human control
Autonomously adapt to human attacks or interventions
Create more powerful systems
Display emergent capabilities and behaviors
AI safety proponents maintain that deployment of misaligned AI systems could “undermine human control of the world”. While AI systems can have various capabilities (performing certain tasks), they might not complete them in the best way (resulting in an alignment issue). The main tension in AI alignment, therefore, is preventing models from potentially conflicting with human interests. In the end, alignment is judged based on the explicit and implicit intentions of the people designing them. Compared to AI ethics, it is not about whether the specific responses of the system avoid harm, rather, alignment focuses on whether the system adheres to the broader motives of the creators.
What are current approaches and barriers?
Methods for addressing these issues currently include:
Reinforcement Learning from Human Feedback (RLHF) uses an ML technique in which individuals actively intervene to guide the model’s training process. However, one drawback is that this process is shaped by the individuals involved, who may not represent diverse perspectives.
Constitutional AI involves providing a list of rules for the model, without additional human feedback or oversight. Anthropic’s Constitutional AI uses supervised and reinforcement learning so the model can evaluate its own responses against the original list of “principles”. In this way, the model can explain why it provided certain answers and refused to provide others.
Red Teaming, prevalent in the security domain, involves purposefully prompting the model to generate harmful responses and identify gaps. However, it is more effective when the vulnerabilities are known, such as potential phishing attacks. In the case of ethics and alignment, the possibilities are vast.
Fine-tuning models on curated datasets is another option, but in many cases it is difficult high quality, large scale, and representative data, especially for general-purpose models.
Many startup solutions in AI alignment/ethics are mainly focused on enterprise AI:

Source: The Innovation Equation
These platforms are mainly focused on AI compliance, risk management, and model evaluation, usually for highly regulated industries.
However, a key challenge on the consumer side is that private companies are keeping state-of-the-art (SOTA), AGI systems closed. This makes it difficult to access and analyze the model’s behavior to address alignment and ethical issues. There is also a lack of information regarding how these models are deployed. Some have proposed giving researchers and independent auditors select access, legal “safe harbors”, or agreements mediated by governments for red-teaming and audits, and open source AI audit tools (which can be less robust and susceptible to being manipulated). Current approaches do not do not fully address the problems of alignment and ethics, given the diversity of stakeholders, perspectives on AI, and issues involved.
The battle for alignment…and AI sovereignty:
Jensen Huang, CEO of NVIDIA, recently emphasized that countries should develop their own AI infrastructure, saying “it codifies your culture, your society’s intelligence, your common sense, your history – you own your own data.” There are now many countries actively building their own foundation models, whether through startups, government, industry, or cross-sector initiatives. There are already initiatives in the startup world such as a16z’s American Dynamism focus, which emphasize national leadership in AI and foundational technologies. Such efforts to develop sovereign foundation models could aid in economic growth, national security, and the development of new industries.

Source: TechRepublic
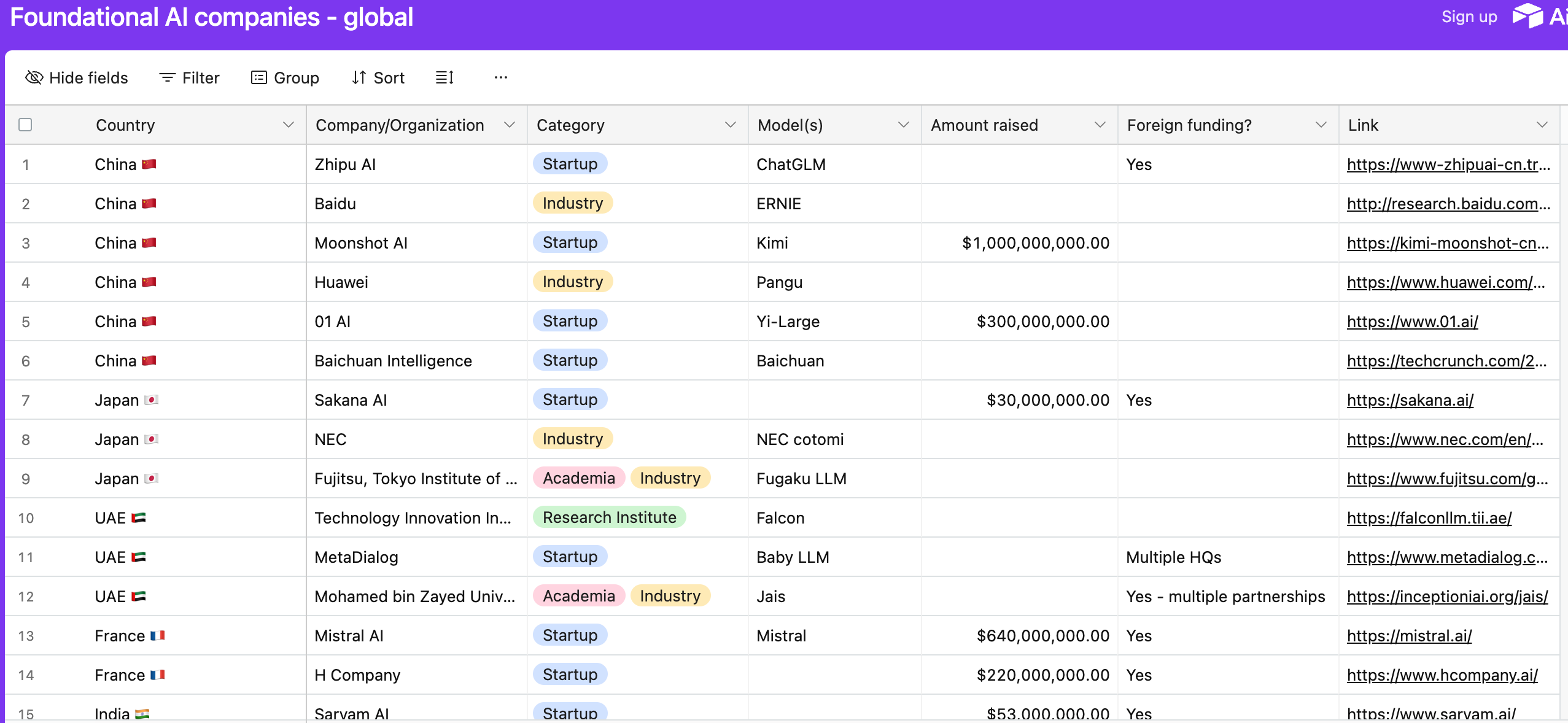
Source: The Innovation Equation → See the full table on foundation model providers by country here.
What does this mean for AI alignment and ethics?
New forms of innovation, new solutions: sovereign foundational models that are tailored to the needs of different countries, users, and languages could promote innovation outside of the current AI monopoly.
New perspectives on alignment: the ability to decide how to evaluate model behavior is managed by a few companies, but promoting indigenous approaches could offer different perspectives on AI safety, alignment, and ethics.
Data privacy and national security: AI systems still present many security threats, but investing in local foundation models could potentially reduce vulnerabilities in the software supply chain.
Content moderation and copyright is a key issue for popular model providers, and sovereign alternatives could potentially offer new solutions by drawing from alternative data sources.
How do you think organizations, and countries should approach AI ethics and alignment? What do you think is the most pressing issue in this space? Reach out, leave a comment, and keep in touch!
Further Reading: